架构师分享:RocksDB使用技巧之分布式存储扩容演进
来源:58架构师
1. 背景
RocksDB是由Facebook公司开源的一款高性能Key Value存储引擎,目前被广泛应用于业界各大公司的存储产品中,其中就包括58存储团队自研的分布式KV存储产品WTable。
RocksDB基于LSM Tree存储数据,它的写入都是采用即时写WAL + Memtable,后台Compaction的方式进行。 当写入量大时,Compaction所占用的IO资源以及对其读写的影响不容忽视。 而对于一个分布式存储系统来说,扩展性尤为重要,但是在扩展的过程中,又不可避免地会涉及到大量的数据迁移、写入。
本篇文章将会着重介绍WTable是如何利用RocksDB的特性对扩容流程进行设计以及迭代的。
2. 数据分布
WTable为了实现集群的可扩展性,将数据划分成了多个Slot,一个Slot既是数据迁移的最小单位。 当集群的硬盘空间不足或写性能需要扩展时,运维人员就可以添加一些机器资源,并将部分Slot迁移到新机器上。 这就实现了数据分片,也就是扩容。

具体哪些数据被分到哪个Slot上,这是通过对Key做Hash算法得到的,伪算法如下:
SlotId = Hash(Key)/N 其中的N就是Slot的总量,这个是一个预设的固定值。
另外,为了让同一个Slot中所有Key的数据在物理上能够存储在一起,底层实际存储的Key都会在用户Key的前面加上一个前缀: 该Key对应的SlotId。 具体方式是将SlotId以大端法转换成2个字节,填充到Key字节数组的前面。
在RocksDB中,除了level 0外,其余level中的sst文件,以及sst文件内部都是有序存储的。 这样一来,WTable也就实现了单个Slot内数据的连续存储,以及所有Slot整体的有序性。

3. 初始扩容方式
WTable初始的扩容方式如下:
1. 添加一个或多个机器资源,并搭建存储服务节点。
2. 制定迁移计划,得到需要迁移的Slot及其节点信息的列表。
3. 循环迁移每个Slot,迁移每个Slot的流程如下图:
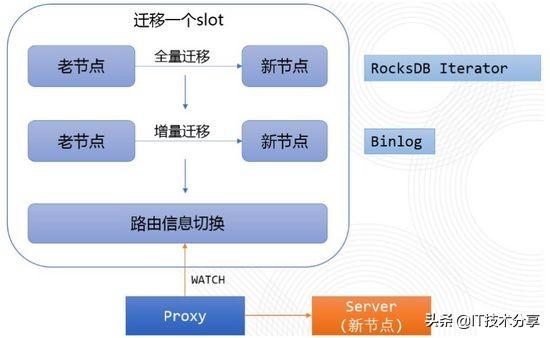
如上图所示,迁移一个Slot可以分成3个阶段: 全量迁移、增量迁移、路由信息切换。
其中全量迁移会在该Slot所在的老节点上创建一个RocksDB的Iterator,它相当于创建了一份数据快照,同时Iterator提供了seek、next等方法,可以通过遍历Iterator有序地获取一定范围内的数据。 对应到这里,就是一个Slot在某一时刻的全量快照数据。 老节点通过遍历Slot数据,将每个Key,Value传输到新节点,新节点写入到自己的RocksDB中。

增量迁移则会利用老WTable节点记录的Binlog,将全量迁移过程中新的写入或更新,传输到新的节点,新节点将其应用到RocksDB。
最后,当发现新老节点上待迁移Slot的数据已经追平之后,则在ETCD上修改该Slot对应的节点信息,也就是路由信息切换。 从此以后,该Slot中数据的线上服务就由新节点提供了。
4. 存在问题
然而,上述的扩容方式在线上运行过程中存在一个问题: 当数据迁移速度较高(如30MB/s)时,会影响到新节点上的线上服务。
深究其具体原因,则是由于一次扩容会串行迁移多个Slot,率先迁移完成的Slot在新节点上已经提供线上服务,而迁移后续的Slot还是会进行全量数据、增量数据的迁移。
通过上个章节的描述,我们可以得知,全量数据是用RocksDB Iterator遍历产生,对于一个Slot来说,是一份有序的数据。 而增量数据则是线上实时写入的数据,肯定是无序的数据。 所以当新节点同时写入这两种数据时,从整体上就变成了无序的数据写入。
在RocksDB中,如果某一个level N中的文件总大小超过一定阈值,则会进行Compaction,Compaction所做的就是: 将level N中的多个sst文件与这些文件在level N+1中Key范围有重叠的文件进行合并,最终生成多个新文件放入level N+1中。 合并的方式可以简单表述为: 如果多个文件中的Key确实有交集,则按照规则进行归并排序,去重,按大小生成多个新sst文件; 如果Key没有交集(说明这次合并,就没有level N+1中的文件参与),则直接将level N中的文件move到levelN+1。
这样我们就可以看出,当大量的整体无序的数据写入迁移新节点时,各level之间的sst文件Key的范围难免会重叠,而其上的RocksDB则会频繁进行大量的,需要归并排序、去重的Compaction(而不是简单的move)。 这势必会占用大量的IO,进而影响读、写性能。
另外,Compaction过多、过重造成level 0层的文件无法快速沉淀到level 1,而同时数据迁移使得新节点RocksDB的写入速度又很快,这就导致level 0中的文件个数很容易就超过阈值level0_stop_writes_trigger,这时则会发生write stall,也就是停写,这时就会严重影响写服务。
5. 扩容方式演进
根据前面的问题描述,我们深入分析了RocksDB Compaction的特点,提出了两点改进思路:
1. 扩容过程中,所有待迁移Slot的全量数据和增量数据要分开传输。
当大量的有序数据写入RocksDB时,由于多个sst文件之间,完全不会出现Key存在交集的情况,所以其进行的Compaction只是move到下一个level,这个速度很快,而且占用IO极少。 所以我们利用这一点,选择把所有Slot的全量数据放在一起迁移,这期间不会有增量数据的打扰,在整体上可以看做是有序的数据。 这就使得在迁移速度很快的时候,也不会占用大量的IO。 而增量数据毕竟是少数,这个过程可以在全量数据传输完成后,以较慢的速度来传输。
2. 考虑到大量数据传输可能会影响线上的服务质量,所以我们决定不再采取每一个Slot数据传输完成后就使其提供线上服务的方案,而是等所有Slot数据都迁移完成之后,再统一提供服务。
根据以上分析,我们最终将扩容分为了3个大的阶段:
1. 全量数据迁移;
2. 增量数据迁移;
3. 路由信息统一切换。
整体流程如下图所示:
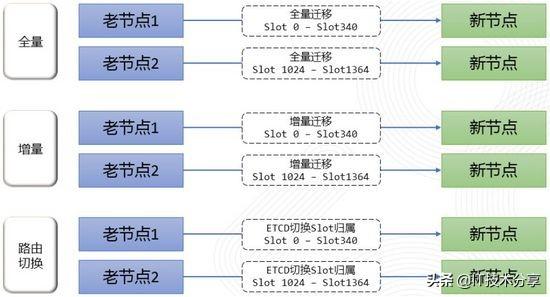
经过上述扩容方式的改进,目前线上WTable集群已经可以进行较高速的扩容,比如50~100MB/s,并且在整个流程中不会对线上服务有任何影响。
6. 其他
在制定方案之初,我们也调研过其他的方案,比如老节点传输sst文件给新节点,后者通过IngestExternalFile的方式将sst文件导入RocksDB。
但是WTable的主备同步是通过Binlog进行的,而当主机通过IngestExternalFile的方式导入数据时,并不会有Binlog产生,也就无法通过正常流程同步数据给备机。 因此如果以此方式实现数据迁移,需要增加新的主备同步方式,这对原有流程是一个破坏,另外也需要比较大的工作量,效率方面也无法保证。
因此我们最终利用RocksDB Compaction的特点设计了适合WTable的快速扩容方案,解决了这个痛点。