通过在线学习进行模版引导的混合执行测试

引用: S. Cha, S. Lee and H. Oh, "Template-Guided Concolic Testing via Online Learning," 2018 33rd IEEE/ACM International Conference on Automated Software Engineering (ASE), Montpellier, France, 2018, pp. 408-418, doi: 10.1145/3238147.3238227.
摘要
我们提出了模版引导的混合执行测试,这是一种在混合执行测试中有效减少搜索空间的新技术。解决路径爆炸问题一直是混合执行测试中的一个重大挑战。人们已经提出了多种搜索启发式方法来缓和这个问题,但仅仅使用搜索启发式方法还不足以大幅提高实际程序的代码覆盖率。本文的目标是补充现有的技术,并通过在混合执行测试中利用模板来获得更高的覆盖率。在我们的方法中,模板是一个部分符号化的输入向量,其工作是减少搜索空间。然而,选择一组正确的模板是不容易的,并且会显著影响我们方法的最终性能。我们提出了一种算法,它可以根据从以前运行的混合执行测试收集来的数据去自动在线学习有用的模板。开源程序的实验结果表明,我们的技术比常规的混合执行测试实现了更大的分支覆盖率,并且更有效地发现漏洞。
一. 引言
混合执行测试是一种流行的能够软件测试方法,它能有效地、系统地实现高代码覆盖率和发现漏洞。混合执行测试的关键思想是同时具体化和符号化地执行程序,其中新的测试用例系统地被生成通过符号化执行被具体化执行强化。近来,混合执行测试已经被用于不同的应用领域,如操作系统、固件和二进制代码等等。
混合执行测试中一个主要的公开挑战是如何有效地探索搜索空间。随着现实程序中执行路径的数量呈指数级增长,混合执行测试必须能够偏重和探索最有可能有利于最终测试结果的路径。然而,有效地引导混合执行测试是不容易的。存在许多不同的以缓解路径爆炸问题为目标的方法:例如路径剪枝方法,搜索启发式方法等。
在本文中,我们提出了模板引导的混合执行测试,这是一种自适应减少混合执行测试搜索空间的新技术。其关键思想是用模板引导混合执行测试,模板通过有选择地生成符号变量来限制输入空间。与常规的混合执行测试(符号化地追踪所有的输入值)不同的是,我们的技术将一组选定的输入值视为符号变量,并将未选定的输入值固定为特定的具体输入值,从而减少了原始搜索空间。然而,我们面临的一个挑战是,如何选择要符号化跟踪的输入值并将剩余的输入值替换为适当的值。为了解决这个挑战,我们开发了一种算法,它在执行混合执行测试的同时自动生成、使用和完善模板。该算法基于两个关键思想。首先,通过使用序列模式挖掘,我们从一组有效的测试用例中生成候选模板,其中测试用例有助于提高代码覆盖率,这些测试用例在执行常规的混合执行测试时被收集。其次,我们使用了一种算法,在混合执行测试过程中从候选模板中学习有效模板。我们的算法根据前几次测试中评估的模板的有效性对候选模版进行迭代得排名。我们的技术与现有的技术是正交的,并且可以与它们(特别是与最先进的搜索启发式技术)进行有效的结合。
实验结果表明,我们的方法在分支覆盖率和漏洞查找方面优于常规的混合执行测试。我们已经在 CREST 中实现了我们的方法,并将我们的技术与中等规模的开源 C 程序(最大 165K LOC)的传统混合执行测试进行了比较。对于所有的基准,我们的技术与常规的混合执行测试相比实现了显著的更高的分支覆盖率。例如,对于 vim-5.7 我们同时进行了 70 个小时的测试,我们的技术完全覆盖了 883 个传统混合执行测试无法覆盖的分支。我们的技术还成功地发现了三个开源 C 程序的最新版本中可能引发的真实漏洞:sed-4.4、grep-3.1 和 gawk-4.21。
本文做出了以下贡献。
1.我们提出了模板引导的混合执行测试。这是一种新的技术,它通过有选择地生成符号化的值来减少输入空间,而不需要任何事先的领域知识。
2.我们提出了一种在线学习算法,以从以前的混合执行测试的运行中选择有用的模板。
3.我们广泛地比较了我们的技术和作用在常规的开源 C 程序上的混合执行测试。我们开源了我们的工具(称为 ConTest)和数据。
二.概述
在本节中,我们用一个例子来说明我们的方法。
2.1 启发性举例
图 1 展示了一个简化自 tree-1.6.0 的代码片段,其中我们假设 strncmp 的主体不可用。函数 f 接收两个字符数组作为输入,命名为输入 1 和输入 2,其中每个数组的长度为 4。程序的执行由这些数组的内容决定。在第 5 行,如果输入 1 的前两个字符是'-'和'X',Xflag 被设置为 1。在第 9 行,如果输入 2 包含字符串"--du",则 duflag 被设置为 1。因此,当函数在以下输入下执行时,可以到达错误位置(第 12 行)。

其中 ∗ 表示一个任意字符。混合执行测试的目标是产生这样的输入以驱动程序执行能够运行到错误位置。
但是,由于搜索空间巨大,常规的混合执行测试不太可能触发错误。为了到达错误位置,程序执行必须成功执行第 5 行和第 9 行。为此,混合执行测试最初用随机输入运行程序,同时用符号输入执行程序。


在执行过程中,符号变量(α1, ... , α8)的约束条件被收集起来,并用于生成下一个输入。例如,当初始执行按照第 4 行的条件语句为真的分支和第 7、11 行的条件语句为假的分支去执行时,以下的约束条件会被收集。

例如,否定最后一个连接条件,将产生使程序执行到第 7 行的第一个条件语句为真的分支的输入。然后,假设新的输入不满足第 7 行的第二个条件,将新生成以下路径条件。
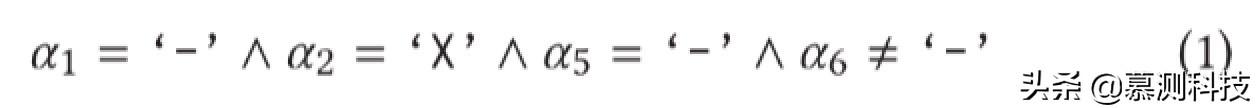
再次否定最后一个连接的条件,混合执行测试成功到达第 8 行条件语句之前的程序位置。但在这个点,它仍然需要探索一个巨大的搜索空间来生成满足条件(!strncmp(...))的输入:因为 strncmp 的主体不可用,符号变量 α7 和 α8 是不受限制的。因此,最后两个字符'du'一定是被偶然的生成且生成概率太低,鉴于从程序入口到第 8 行已经存在多条(更确切的来说,9 条)。
我们的模板引导的混合执行测试旨在有效和自动地减少搜索空间。在混合执行测试过程中,我们的技术会自适应地生成模板,这些模版通过有选择地引入符号变量从而被用来限制输入空间。例如,当它被应用到图 1 中的程序中时,我们的技术会自动生成以下模板来限制搜索空间。

也就是说,除了最后两个输入值之外,所有的输入值都由具体的值固定下来,这样,混合执行测试就不再无谓地试图探索无法到达第 8 行的那些执行路径。换句话说,我们的技术能够强制执行到达错误位置的必要条件,使得混合执行测试能够专注于分别生成 α7 和 α8 的输入'd'和'u'。通过该模板,混合执行测试能够更有效地生成能够触发错误的输入,比传统方法在示例程序中的速度快 9 倍。
2.2 模板引导下的在线学习混合执行测试
图 2 说明了我们的技术在用于执行混合执行测试同时在线自动生成模板。我们的技术能够在不需要任何事先的领域知识的情况下生成有效的模板。该算法重复以下五个过程,直到给定的测试预算用完。

2.2.1 常规的混合执行测试。我们首先执行常规的混合执行测试(无模板),以生成一组有效的测试用例。如果一个测试用例能够在混合执行测试过程中行使之前未覆盖到的分支,我们就说它是有效的。我们在一定时间内运行混合执行测试,收集有效的测试用例。例如,当我们对图 1 中的示例程序运行几分钟的混合执行测试时,我们可以收集到超过 40000 个有效的测试用例,例如以下的测试用例:

2.2.2 序列模式挖掘。一旦收集到有效测试用例的数据集,我们就会尝试捕捉这些输入向量中的共同模式。具体来说,我们的目标是提取有效测试用例中经常出现的部分字符序列。为此我们使用了一种最新的序列模式挖掘算法,它从上一阶段收集到的 40000 个测试用例中找出以下四种模式:

例如,模式 P1 表示有效测试用例很可能依次包含字符'-'、'X'、'-'。
2.2.3 模式排序。在通过序列模式挖掘生成候选模式后,我们选择最有可能最大化独特分支覆盖范围的前 k 种模式;该覆盖范围的计算方法是常规的混合执行测试没有发现的分支数量。在我们的例子中为了快速覆盖独特分支(例如图 1 中第 8 行的判断为真的分支),需要使用图 2 中的模式 P3。然而,在候选者中精确定位有效模式是不容易的,因为在现实程序上运行算法通常会发现成千上万的模式。更糟糕的是,只有一小部分候选模式对增加分支覆盖范围是有效的。我们通过根据之前运行中评估的类似模式的有效性对候选模式进行排名来解决这一挑战。我们在算法过程中积累了一些好的和坏的模式集合,利用它们来估计新生成的模式的有效性。对于示例程序,当 k=2 时,我们选择 P3 和 P2 这两种候选模式。
2.2.4 模式到模板。下一个步骤是将模式转化为模板。请注意,模式只是一个有意义的输入值(如字符)的有序序列;要变为模板,我们需要决定给定模式中包含的每个值的位置。为此我们首先收集包含了模式的测试用例,然后确定模板值出现频率最高的位置。例如,假设具体值'X'在测试用例中的第二个索引处出现得最多。那么,我们将输入 2 中第二个索引处的符号值 α2 替换为具体值'X'。通过将这一规则应用于前一阶段选择的模式 P3 和 P2,我们得到以下两个模板:

在本文的其他部分,我们也用一组具体值及它们的位置来表示一个模板。例如,第一个模板可以表示如下:

2.2.5 带模版的混合执行测试。最后一步是用生成的模板(T1 和 T2)进行混合执行测试。例如,当使用模板 T1 时我们只生成四个符号值(α3, α4, α7, α8),其余的用模板 T1 中的具体值代替。需要注意的是,这些具体的值并不是任意的,而是通过强制程序执行沿着特定的路径(取第 4 行和第 7 行条件语句判断为真的所有分支)从而有效地引导混合执行测试到达错误发生的地点(如图 1 中第 11 行判断为真的分支)。
在对模板进行了一段时间的混合执行测试后,我们用覆盖到的独特分支的数量来评估生成模板的质量。作为结果,我们将图 2 中相应的模式分为好模式和坏模式,这种反馈将被排名算法在下一次算法迭代中使用。在整个过程中,我们的算法会积累评价数据并因此排名算法能够根据这些增加的知识挑选出更有效的模式。
三.在线学习的模板指导下的混合执行测试
在本节中,我们介绍了我们的算法(算法 2),用于执行模板引导下的混合执行测试,同时在线自动生成有效模板。算法 2 由四个主要阶段组成:常规的混合执行测试、序列模式挖掘、排名和模板引导的混合执行测试。在第 2 行,算法从初始化数据开始。集合 B 和 TB 分别代表传统的混合执行测试和模板引导的混合执行测试所覆盖的分支。集合 Good 和 Bad 分别表示有效和无效的输入模式。

该算法有三个超参数(η1、η2 和 η3)。第一个参数 η1 在第 6 行被使用,决定第一阶段的常规的混合执行的执行次数。第二个参数 η2 在第 23 行被使用,表示每个模板的混合执行的执行次数。最后一个参数 η3 表示模式 p 成为好模式(即被包含在集合 Good 中)的阈值。在实验中,我们设置 η1=100,η2=20,η3=20。在这项工作中,我们通过试错对这些超参数进行了手动调整并发现算法 2 的性能很大程度上取决于这些参数。未来一个有趣的方向是在算法过程中自动寻找最优超参数。















